
FaceFilter: Audio-Visual Speech Separation using Still Images
| Author | Soo-Whan Chung, Soyeon Choe, Joon Son Chung, Hong-Goo Kang |
| Publication | INTERSPEECH |
| Month | October |
| Year | 2020 |
| Link | [Paper] [Project] |
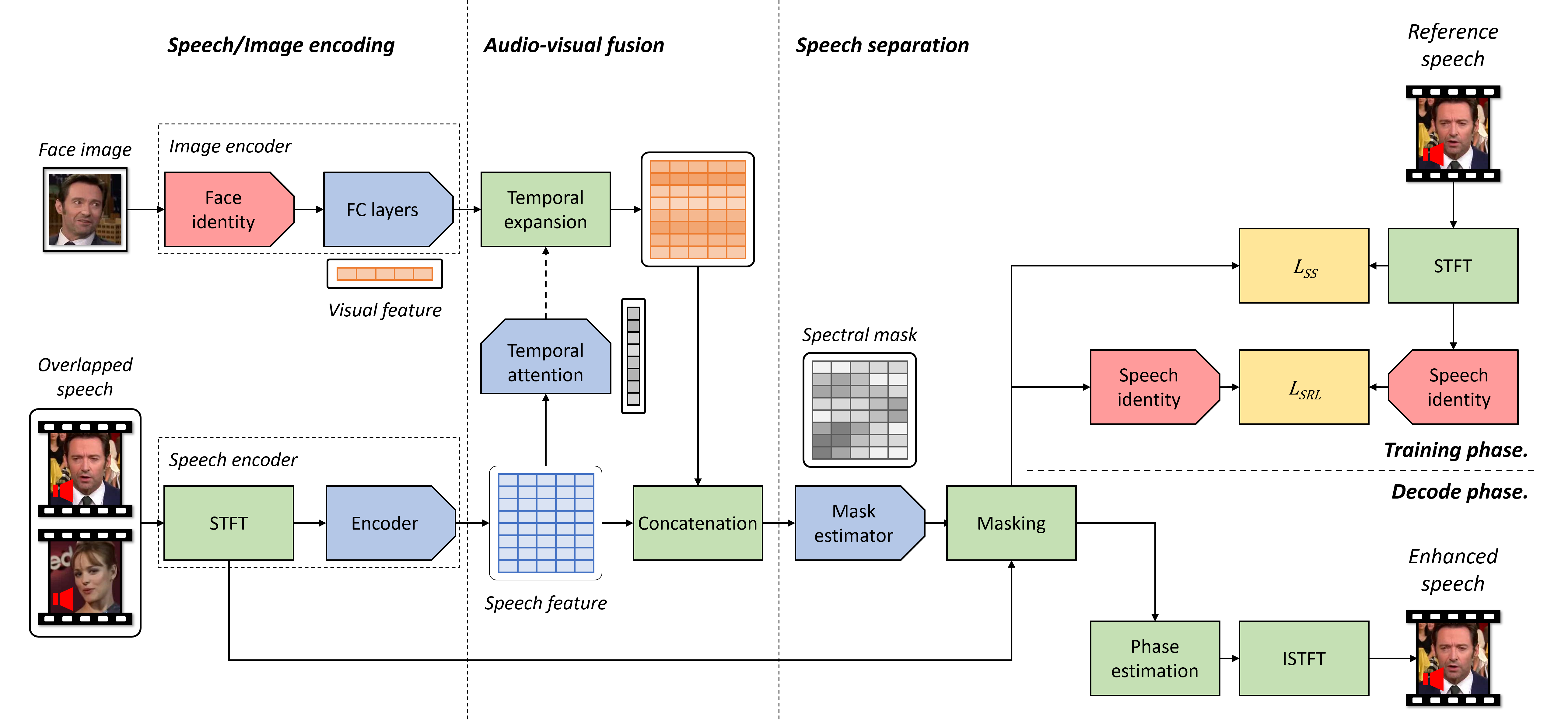
Description of the proposed audio-visual speech separation network. Blue blocks are trainable neural networks whereas the red blocks are networks pre-trained in cross-modal biometric task.
ABSTRACT
The objective of this paper is to separate a target speaker’s speech from a mixture of two speakers using a deep audio-visual speech separation network. Unlike previous works that used lip movement on video clips or pre-enrolled speaker information as an auxiliary conditional feature, we use a single face image of the target speaker. In this task, the conditional feature is obtained from facial appearance in cross-modal biometric task, where audio and visual identity representations are shared in latent space. Learnt identities from facial images enforce the network to isolate matched speakers and extract the voices from mixed speech. It solves the permutation problem caused by swapped channel outputs, frequently occurred in speech separation tasks. The proposed method is far more practical than video-based speech separation since user profile images are readily available on many platforms. Also, unlike speaker-aware separation methods, it is applicable on separation with unseen speakers who have never been enrolled before. We show strong qualitative and quantitative results on challenging real-world examples.