
Look Who’s Talking: Active Speaker Detection in the Wild
| Author | You Jin Kim, Hee-Soo Heo, Soyeon Choe, Soo-Whan Chung, Yoohwan Kwon, Bong-Jin Lee, Youngki Kwon, Joon Son Chung |
| Publication | INTERSPEECH |
| Month | August |
| Year | 2021 |
| Link | [Paper] |
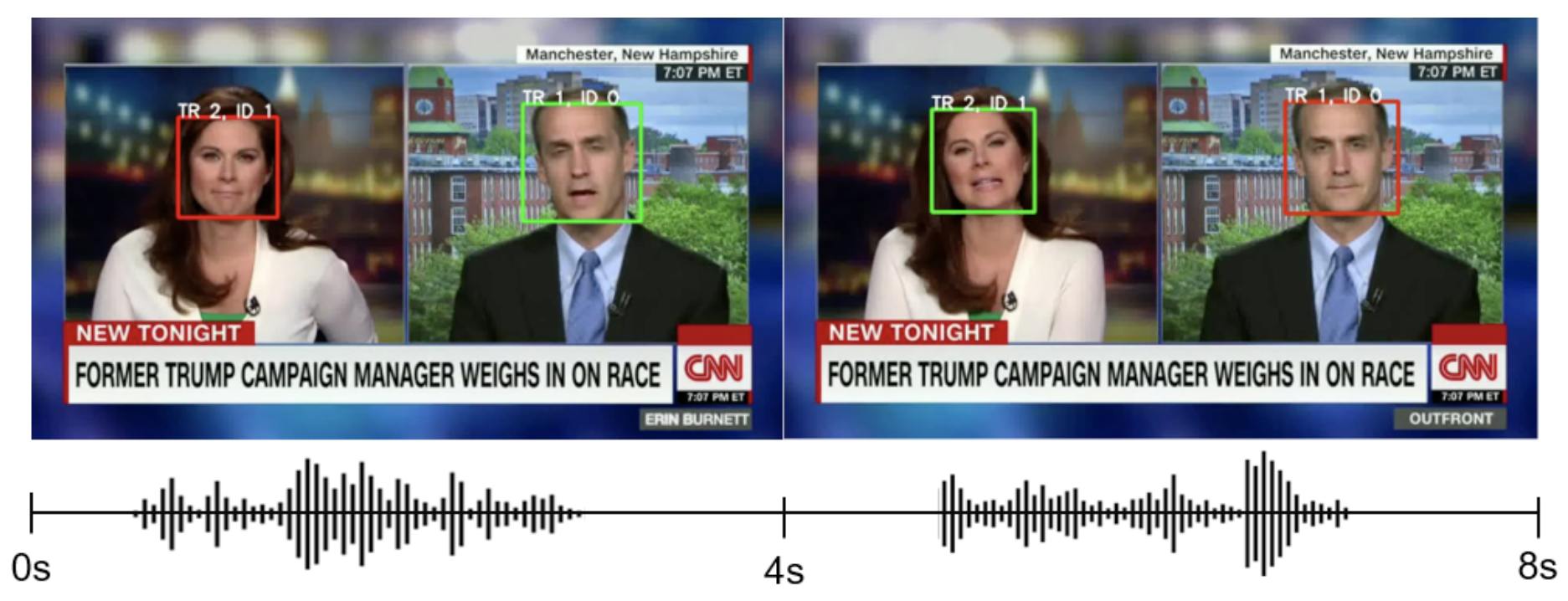
Who is speaking? ASD detects when a person is speaking. The person who is active is in green boxes, and nonactive is in red. Between 0 and 4 seconds, the left woman is speaking (active), and the right man is not speaking (non-active). On the other hand, between 4 and 8 seconds, the left woman is not speaking (non-active), and the right man is speaking (active).
ABSTRACT
In this work, we present a novel audio-visual dataset for active speaker detection in the wild. A speaker is considered active when his or her face is visible and the voice is audible simultaneously. Although active speaker detection is a crucial pre-processing step for many audio-visual tasks, there is no existing dataset of natural human speech to evaluate the performance of active speaker detection. We therefore curate the Active Speakers in the Wild (ASW) dataset which contains videos and co-occurring speech segments with dense speech activity labels. Videos and timestamps of audible segments are parsed and adopted from VoxConverse, an existing speaker diarisation dataset that consists of videos in the wild. Face tracks are extracted from the videos and active segments are annotated based on the timestamps of VoxConverse in a semi-automatic way. Two reference systems, a self-supervised system and a fully supervised one, are evaluated on the dataset to provide the baseline performances of ASW. Cross-domain evaluation is conducted in order to show the negative effect of dubbed videos in the training data.